
python으로 공간 데이터 시각화를 하는 방법은 두 가지가 있습니다.
- matplotlib
- plotly
과학자들은 matplotlib으로 그래프를 그리는 것이 익숙합니다.
공간 데이터 시각화에도 matplotlib 기반으로 많이 접근합니다.
plotly는 지도를 그려놓고 그 위에서 공간 데이터를 시각화합니다.
오늘 할 이야기는 matplotlib을 기반으로 공간 데이터를 시각화하는 얘기, 그 중에서도 Basemap을 사용하는 방법에 대해 알아보고자 합니다.
왜 Basemap이냐?
matplotlib기반 공간 정보 시각화 방법에는 cartopy와 basemap이 있습니다.
이때까지는 cartopy를 많이 썼습니다.
제가 matplotlib 기반으로 그래프는 많이 그려봤지만 cartopy는 그 명성은 익히 들었지만 거의 사용해 본 적이 없었습니다.
일단 무겁고, 설치 환경에서 자꾸 환경 설정에 실패했기 때문입니다.
그 대안으로 어떤 라이브러리를 사용할 까 고민하던 와중에 발견한 것이 Basemap입니다.
cartopy와 basemap의 차이점은 다음과 같습니다.
둘 다 matplotlib 기반이지만, basemap은 matplotlib에서 만든 라이브러리고 cartopy는 그 기반이 matplotlib이지만 자체 생태계를 구축했습니다.
저도 basemap이 matplotlib에서 만든 줄은 이번에 글을 쓰기 위해 자료를 찾아보던 중 알게 되었습니다.
basemap 공식 문서
어떻게 사용하는가?
GEOS Projection?
이번 포스팅에서는 GEOS Projection을 따르는 위성 영상을 시각화 하기 위해서 basemap을 사용합니다.
GEOS Projection이 뭔지에 대해서는 아래 링크를 참조하세요.
GEOS
쉽게 얘기하자면 위성 영상이 전 지구(Full Disk)를 찍은 모습을 나타내는 projection입니다.
아래 그림처럼요.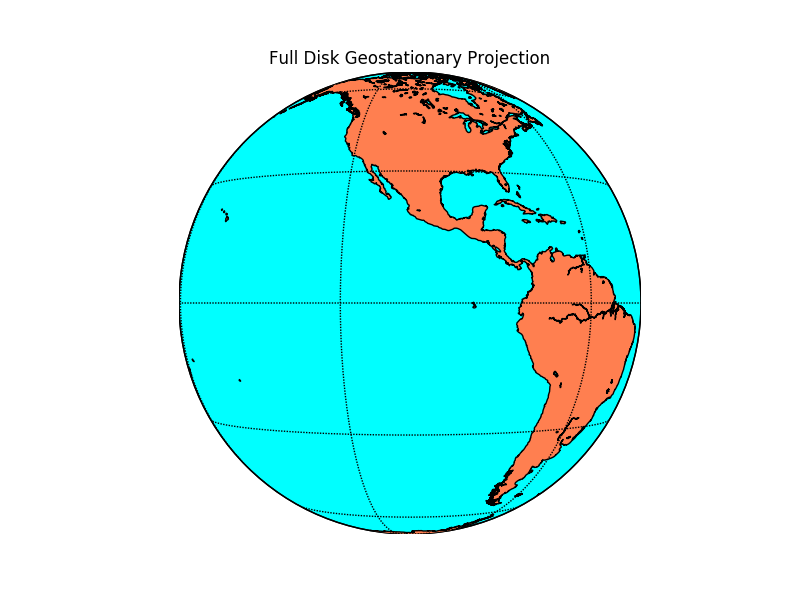
이 projection을 나타내는 Proj string은 다음과 같습니다.
+proj=geos +h=35785831.0 +lon_0=128.2 +sweep=ylon_0은 세로로 지구본을 얼마나 돌릴 건지 결정합니다.
설치
- 설치 링크 : https://matplotlib.org/basemap/
- pip install : https://pypi.org/project/basemap/
- basemap-data-hires : 라이브러리 사용 시 high-resolution 자료들(해안선 등)을 지도에 쓰려면 반드시 설치해야 합니다.
- 기본 해상도 데이터는 basemap-data로 basemap 설치할 때 같이 깔립니다.
python -m pip install basemap python -m pip install basemap-data-hires
사용 예시
기본 GEOS 표출

from mpl_toolkits.basemap import Basemap, cm
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
m2 = Basemap(rsphere=(6378137.00,6356752.3142), projection='geos',lon_0=128.2,resolution='h')
m2.drawcoastlines()원하는 영역만 표출하기

lat1, lat2, long1, long2 = (46.830415916691464,
-16.043669898267705,
90.29636166074948,
172.08684795392023)
plt.figure(figsize=(10,10))
'''
llcrnr : left lower corner
urcrnr : upper right corner
resolution : basemap에서 제공하는 해안선 등의 데이터를 어떤 해상도로 표출할 지 결정. h면 high resolution을 의미
lon_0 : longitude 방향으로 중앙
lat_0 : latitude 방향으로 중앙
'''
m= Basemap(llcrnrlon=long1,llcrnrlat=lat2,urcrnrlon=long2,urcrnrlat=lat1, resolution='h',epsg=4326,lon_0=(long2-long1) / 2,lat_0=(lat1-lat2) / 2)
m.drawcoastlines()표출 예시
NOAA에서 제공하는 GOES위성의 어떤 밴드 영상을 단순 시각화한 예시
결론
Cartopy보다 덜 무거우면서도 친숙한 인터페이스 내에 Projected map을 사용하고 싶다면 basemap 사용을 고려할 것.
그리고 기초편이 있다는 것은 심화 편도 있다는 얘기.
심화 편에서는 그렇다면 cartopy에서 그리던 것들을 어떻게 basemap 코드로 옮길 수 있는데?에 대해 쓸 예정입니다.
일하면서 틈틈히 메뉴얼을 작성하고 그 메뉴얼을 더 다듬어서 틈나는 대로 블로그 포스팅을 하다 보니 시간이 좀 걸립니다.
Reference
- geostationary projection에 대한 자세한 정보 : https://proj.org/en/9.3/operations/projections/geos.html
- basemap의 메뉴얼 중 geostationary projection에 대한 샘플 코드와 설명 : https://matplotlib.org/basemap/users/geos.html
- basemap의 여러 기본 사용법을 나열한 곳. Python Data Science Handbook 내 실려있는 코드의 일환인것으로 보임 : https://jakevdp.github.io/PythonDataScienceHandbook/04.13-geographic-data-with-basemap.html
- 여기서는 conda 환경에서 basemap을 설치하라고 하는데 왠만하면 conda 환경 구축을 피하고 싶었다.
- numpy에서 투명도 조절하기 : black to transparent alpha image with numpy
'Develope > GIS' 카테고리의 다른 글
| [GIS] gcp로 georeference 하기, lcc 좌표계에서 EPSG:4326으로 reproject 하기 (1) | 2023.02.28 |
|---|---|
| [ArcGIS] ArcGIS python API 기초 예제 (2) | 2023.01.31 |
| [QGIS] QGIS annotation layer (with QGIS 3.22) (0) | 2022.11.18 |
| [GIS] 당신이 겪을 수 있는 georeference 문제들과 내 해결법 (0) | 2022.11.16 |
| [KML] Python으로 KML 쓰기, 읽기, 수정하기 (0) | 2022.02.08 |








